YaCy
![]() Yacy is a free software peer-to-peer distributed search engine program written in Java. You can run it on your desktop or a server. It crawls websites and makes a searchable index which is shared among other peers. Searches are done by looking at the local index while also querying other peers in the network for results. In theory and principle it's exactly what the Internet lacks and should have; a censorship-resistant unbiased all-finding all-knowing distributed search engine. In practice it is totally unusable as a general-purpose search engine due to few relevant search results presented in seemingly random order. However, it can be useful for researchers and more specialized use-cases.
Yacy is a free software peer-to-peer distributed search engine program written in Java. You can run it on your desktop or a server. It crawls websites and makes a searchable index which is shared among other peers. Searches are done by looking at the local index while also querying other peers in the network for results. In theory and principle it's exactly what the Internet lacks and should have; a censorship-resistant unbiased all-finding all-knowing distributed search engine. In practice it is totally unusable as a general-purpose search engine due to few relevant search results presented in seemingly random order. However, it can be useful for researchers and more specialized use-cases.
 | |
| Developer(s) | Michael Peter Christen |
|---|---|
| Initial release | 2005 |
| Stable release | 1.9
/ 2016 |
| Operating system | Java (Platform independent The GNU Operating System, Windows, Mac OS X, etc)GNU/Linux |
| Type | Search Engine |
| License | GPL |
| Website | http://www.yacy.net |
Features and usability[edit]
YaCy acts as a web server which provides a page which looks like a typical search-engine. It will by default be listening at 127.0.0.1:8090 and you can go there and immediately do your searches once it's installed.
You will very quickly notice some of it's deal-breaking flaws if you configure it to be your browsers default search engine and use it for all your searches.
The search-results are lacking and they appear to be ordered by /dev/urandom. It simply fails at providing useful results. That's a big problem with a search engine.
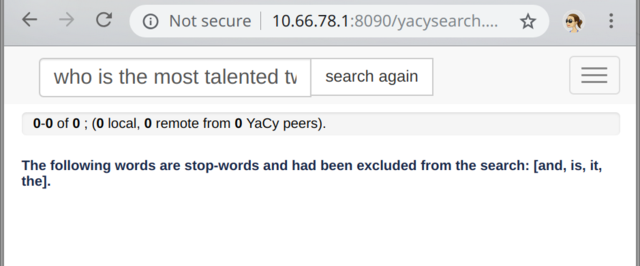
Further, YaCy doesn't even provide any results half the time. It loves to just time out. This is very typical and almost a rule not an exception when a search query has more than two words. It may manage to produce some random results for a simple query for Twice (none of which will be about that k-pop group) but a query for who is the most talented Twice member and why is it Nayeon will make it's search thread crash and the search result page will be blank.
Resource-use is also a problem. Leave YaCy running for a while and sooner or later it will decide to peg one CPU core at 100% permanently. It will also, over time, use up all storage it has access to until there is no more unless you specifically configure it to not grow above a given size.
This is not the kind of review we like to write. The first revision of this page was written in 2007. We pointed out it's performance-problems and the fact that "it doesn't do a very good job at sorting the pages according to relevance". In 2019, 12 years later, we have no choice but to conclude that YaCy is a completely useless piece of software. And that's just sad because there is a rapidly increasing need for a uncensored unbiased peer to peer based search engine.
Specialized use-cases[edit]
"I do internet research in many areas. Primarily Alternative Energy, Organic Agriculture and Esoterica. What I love about YaCy is what you apparently consider one of its many flaws.
If I want to see something on one of my favorite subjects, Stirling Engines, Google always returns the same websites in the same order so I have to navigate through several pages of results and in actuality han't seen anything new on the subject from Google in some years. It's just too time consuming to bother with.
With YaCy, because results are random, or hand picked by other peers, I immediately found several new links chock full of interesting information about Stirling Engines on the first page of results. Another search sometime later had the same results. More new stuff I had never seen before searching page after page of the same old prioritized, commercial oriented Google results such as where to buy some cheap knock off Stirling engines on Amazon or Ebay.
With YaCy I found more of the kind of information I want to find. Projects and ideas from other Stirling Engine enthusiasts and Stirling Engine model builders, further, I could spider entire domains about Stirling Engines and quickly locate dozens of other good recommended links and all my favorite sites would be saved locally making them easy to find with a subsequent search without bookmarking.
Doing research I'm generally looking for new information, With YaCy, finding some new quality information is easier and faster."
The technology[edit]
YaCy distributes uses a distributed hash table (DHT) to share a reverse word index (RWI) among peers in the network.
The concept and the technology itself is very appealing and interesting.
Searx+Yacy: A Huge Disappointment[edit]
Searx is a metasearch engine program written in Python which actually works. It does lack of any index of it's own which makes it prone to censorship and blacklisting by search-engines due to too many queries from one source. So why not add a full-featured distributed search-engine like YaCy to Searxs sources? That sounds like a the perfect combination.
In practice it's just not worth having a local YaCy instance as a Searx source. YaCy will be the slowest responding source and most of the time it won't respond at all which results in Searx waiting the maximum time YaCy's allowed before producing results.
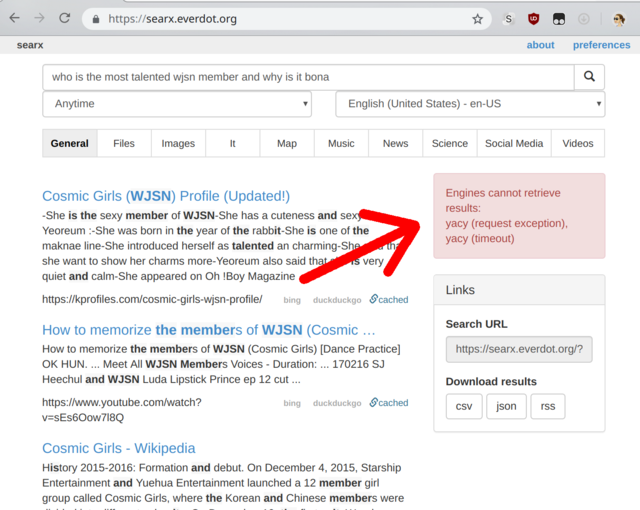
Searx is almost a better experience without YaCy as a source. The few results YaCy adds to the mix the few times it does produce something are not useful and the added response-time from Searx when YaCy is used as a source is noticeable. And the most of the time shown warning about "Engines cannot retrieve results: yacy" is annoying.
One trick to combining Searx with YaCy is to limit the timeout for YaCy in settings.yml to timeout : 3.0 - which may seem counter-intuitive. YaCy should, in theory, work better if it gets 30 seconds in instead of 3 seconds to produce results. In practice YaCy tends to either produce results quickly or timeout regardless of it being given 10 or 20 or 30 seconds. Thus; the only difference between a timeout of 30 seconds over 3 seconds is that Searx produces results quicker.
Do note that while we don't recommend using YaCy as a Searx source since YaCy is quite useless we actually do use it as a Searx source. Because.. it's a free search engine and a cool technology. It is not very practically beneficial or profitable; but it's cool.
The technical details showing exactly why YaCy is a useless piece of horrid software[edit]
The search results produced by YaCy are, as mentioned, seemly presented in random order. A close-up inspection of source/net/yacy/search/query/SearchEvent.java reveals why: The search results produced by the first YaCy node on the YaCy network are shown in the order they are ranked by that node. Let's say the fastest responding node produces three results ranked with the scores 5, 2 and 1 and the second node responds with four results ranked with scores of 8, 7, 6 and 4. If higher is better then one would assume the first three results from the second peer show up as the first three results and the best result from the first node would be result number four. That's simply not the case; the results from the first peer (ranked 5, 3 and 1) will be the first three results and the following results will be the ones from the second peer. This can be changed:
@@ -2119,16 +1986,21 @@
}
this.localsolroffset += nextitems;
}
-
- // now pull results as long as needed and as long as possible
- if (this.remote && item < 10 && this.resultList.sizeAvailable() <= item) {
- try {
- Thread.sleep(100);
- } catch (final InterruptedException e) {
- log.warn("Remote search results wait was interrupted.");
- }
- }
-
+
+ // Present results after remotesearch.maxcount and stop remote search threads
+ if (this.remote && item == 0) try {
+ Thread.sleep ( Switchboard.getSwitchboard().getConfigInt("remotesearch.maxtime", 3000) );
+ } catch (final InterruptedException e) {ConcurrentLog.logException(e);}
+ if (this.nodeSearchThreads != null) {
+ for (final Thread search : this.nodeSearchThreads) {
+ if (search != null) {
+ synchronized (search) {
+ if (search.isAlive()) {search.interrupt();}
+ }
+ }
+ }
+ }
+
final int resultListIndex;
if (this.remote) {
resultListIndex = item;
YaCy already has a configuration option called remotesearch.maxtime - it's just honored anywhere. Using this value as a fixed limit for how long YaCy waits for remote search results to arrive before presenting them provides a more consistent experience. The downside of this approach is that a limit of say 6 seconds (remotesearch.maxtime=6000) makes YaCy always wait 6 seconds before any result is shown. Do note that this will only work if remote Solr queries have a similar limit (outlined below).
YaCy's tendency to randomly decide to spend up to one minute before it presents results is another annoyance which makes it kind of crappy. This is due to a time-out of 1 minute when it connects to remote nodes and accesses their Solr index. This can be changed by editing source/net/yacy/search/SwitchboardConstants.java to use remotesearch.maxtime instead of a special time-out value for Solr,
--- /home/oyvinds/src/yacy-original-git/yacy_search_server/source/net/yacy/search/SwitchboardConstants.java 2019-09-06 15:23:15.076930812 +0200
+++ source/net/yacy/search/SwitchboardConstants.java 2019-09-11 16:00:51.722521758 +0200
@@ -319,7 +319,9 @@
public static final String FEDERATED_SERVICE_SOLR_INDEXING_URL = "federated.service.solr.indexing.url";
public static final String FEDERATED_SERVICE_SOLR_INDEXING_SHARDING = "federated.service.solr.indexing.sharding";
public static final String FEDERATED_SERVICE_SOLR_INDEXING_LAZY = "federated.service.solr.indexing.lazy";
- public static final String FEDERATED_SERVICE_SOLR_INDEXING_TIMEOUT = "federated.service.solr.indexing.timeout";
+ //
+ // oyvinds edit : use remotesearch.maxtime instead of federated.service.solr.indexing.timeout
+ public static final String FEDERATED_SERVICE_SOLR_INDEXING_TIMEOUT = "remotesearch.maxtime";
public static final String FEDERATED_SERVICE_SOLR_INDEXING_WRITEENABLED = "federated.service.solr.indexing.writeEnabled";
/** Setting key controlling whether a self-signed certificate is acceptable from a remote Solr instance requested with authentication credentials.
YaCy's tendency to be very unpolite when it crawls websites is another problem. It does respect a crawl-delay value if a website has set one in it's robots.txt. Websites with no robots.txt asking for a limit get none; YaCy will effectively behave like a denial of service attack. A look at source/net/yacy/cora/protocol/ClientIdentification.java reveals some very small limits. These can be increased by changing a few lines:
- public static final int clientTimeoutInit = 10000;
- public static final int minimumLocalDeltaInit = 10; // the minimum time difference between access of the same local domain
- public static final int minimumGlobalDeltaInit = 500; // the minimum time difference between access of the same global domain
-
+ // yacy default 10 seconds, too long to wait - try 2 seconds
+ public static final int clientTimeoutInit = 2000;
+ // yacy uses a default of 10 which is very unpolite. Use 2000 (2 seconds) instead
+ public static final int minimumLocalDeltaInit = 2000; // the minimum time difference between access of the same local domain
+ public static final int minimumGlobalDeltaInit = 2000; // the minimum time difference between access of the same global domain
+
public static class Agent {
public final String userAgent; // the name that is send in http request to identify the agent
public final String[] robotIDs; // the name that is used in robots.txt to identify the agent
This file is also where a custom user-agent should be set. YaCy does have a configuration option for it but that setting isn't actually used.
There is a staggering amount of additional things which need to be changed and fixed for YaCy to become anything remotely resembling a realistic alternative to today's dominant search engines.
Search and usage tips[edit]
YaCy supports searching by language and a lot of other metrics too. It uses it's own special /switches. A search limited to English can be done by adding /language/en to a search (wjsn /language/en).
Searches can be limited to a given site with site:example.tld and file-types can be search with filetype:extension (filetype:webm).
HOWTO install YaCy on Fedora[edit]
First, install Java using dnf as root:
dnf -y install java-latest-openjdk-headless
You can find out what the latest released version is the latest by visiting https://yacy.net/en/ - as of now that's a version from 2016. There is also a secret folder with snapshots available at luccioman's github page and that's a better choice.
First, login to your server and go root and make a user for Yacy with a home folder in /home/yacy:
adduser --system yacy -m -d /opt/yacy
Now it's time to install lynx if you do not have that text-based browser.
Switch to the yacy user you created,
su - yacy
You should now be in the folder /home/yacy and you can verify that you are with pwd
Now it's time to download and unpack it. Get either the stable version from 2016:
wget https://yacy.net/release/yacy_v1.92_20161226_9000.tar.gz tar xfvz yacy_v1.92_20161226_9000.tar.gz -C ..
Or a newer development version (recommended):
wget https://github.com/luccioman/yacy_search_server/releases/download/Release_1.921.9828-dev/yacy_v1.921_20181121_9828.tar.gz tar xfvz yacy_v1.921_20181121_9828.tar.gz -C ..
Why add -C ..? The tarball contains a folder called yacy/. Asking tar to go one folder down results in the contents being extracted to /home/yacy.
You can now start your server by running
./startYACY.sh
You should get a message saying
>> YaCy started as daemon process. Administration at http://localhost:8090 <<
Now it's time to point a text-based browser like lynx, links or w3m to http://localhost:8090 and configure an admin password.
- Run
lynx http://localhost:8090/ - Go to and press enter on "(BUTTON) Administration"
- Scroll down and choose "Use Case & Account"
- Next, scroll down and choose "Accounts" under "Use Case & Account"
- Check the box next to Access only with qualified account!
- Scroll down a bit further to User Administration and Admin Account and set a password for Admin. You could change username too.
- Select "Define Administrator" and press Enter
- Press
qto quit lynx.
 |
Note: Make sure Access only with qualified account is checked. Revisit lynx http://localhost:8090/ and make sure if you have any doubt you changed that setting. The reason this is so vital is that Searx will be coming from localhost when it is accessing YaCy. The same is true if you run something like a hidden Tor service.
|
Now it's time to create a systemd file for YaCy. Type exit to leave the YaCy user and create a systemd service file:
[Unit] Description=YaCy search server After=network.target [Service] Type=forking User=yacy ExecStart=/home/yacy/startYACY.sh ExecStop=/home/yacy/stopYACY.sh [Install] WantedBy=multi-user.target
reload systems services
systemctl daemon-reload
and start YaCy:
systemctl --user start yacy.service
systemctl start yacy.service
verify that it's running with
tail -n 50 /opt/yacy/DATA/LOG/yacy00.log
To be able to stop YaCy using systemd you have to add a line with the password to the top of stopYACY.sh in YaCy's root folder:
export YACY_ADMIN_PASSWORD="yoursecretpassword"
This isn't all that safe but the alternative is to set YaCy to allow unrestricted access from localhost. You could that but you will have a problem if you combine it with something like Searx or Tor which would be talking to YaCy from localhost.
Lastly, you may want to point a browser at 127.0.0.1:8090 or the machines IP:8090 and play around with some of the settings. Good luck.
Essential configuration[edit]
We strongly recommend changing some of the default "delay" values if you plan to run YaCy use it for web crawling.
Go to the administration panel and choose System Administration and then the Performance Settings of Busy Queues tab. Change the delay values for Local Crawl and Remote Crawl Job to 10000 for "Delay between idle loops" and "Delay between busy loops" to 3000 which equals 3 seconds. The robots standard dictates that a web crawler should wait 3 seconds between requests. YaCy doesn't do that by default which is why a lot of sites outright ban it.
YaCy has some "special" configuration options available by going to "System Administration" and clicking "Advanced Properties". This will present a list of text strings similar to the about:config interface in Mozilla Firefox. Changing the postprocessing.maximum_load to something like the number of cores on your system minus one is likely a great idea. The reason is that the default value of 2.5 results in no postprocessing ever when YaCy is running on a multi-core system. If you have a dual-core then 2.5 is probably fine. If you have 6 cores and 12 threads on the machine YaCy is running on you'll want a higher value. YaCy's results will be (a lot) better when postprocessing is done.
Do note that a lot of the options there do absolutely nothing. As an example, changing crawler.userAgent.string does not actually change anything at all. You can use a user-agent which points to a page informing webmasters why you are crawling. YaCy will instead leave a string with the specific kernel version you are using - which is a huge security as well as a privacy risk.
Entries per word[edit]
Under Index administration there is a tab named Reverse Word Index where "Limitation of number of references per word" is by default set to 100. Increasing it to 1000 is a good idea.
Multiple YaCy instances used by Searx[edit]
The System Administration link Debug/Analysis Settings opens a settings page where it is possible to configure Search data sources. It may be wise to uncheck everything but Local Solr index if you are configuring a YaCy instance which will be one of multiple YaCy instances used by a front-end like Searx.
links[edit]
- YaCy's homepage is at https://yacy.net/
- The version listed on the homepage is from 2016
- There are newer "snapshot" releases at https://github.com/luccioman/yacy_search_server/releases/
We are currently still running a YaCy+Search instance at searx.everdot.org. Any search there will include results for yacy. It is also possible to just search the YaCy back-end using the !yacy prefix to searches (!yacy wjsn save you save me to search for WJSN's wonderful hit-single "Save You, Save Me").
While it's kind of pointless since YaCy is kind of useless it is the best peer to peer software simply because it's the only peer to peer search engine solution. It is quite sad that it's as bad as it is.

Enable comment auto-refresher
Anonymous (e78a345c)
Permalink |
Anonymous (5e0bfb92)
Anonymous (79f5e4ef2c)
Eloxer
Anonymous (ce66c28fdb)
Permalink |
Anonymous (42b8214ffa)
Permalink |